I was looking for a method to sort a really large data-set alphabetically without eating all a user’s RAM, or using disk space, nor have a user sit and wait for N² comparisons.
I found the answer in the form of a Trie-tree, a neat data structure that flattens ASCII characters into... well a tree.
Lets say we have the following words:
- Ape
- App
- Apple
- Orange
- Ore
- Pear
A Trie Tree would represent the data in the following way:
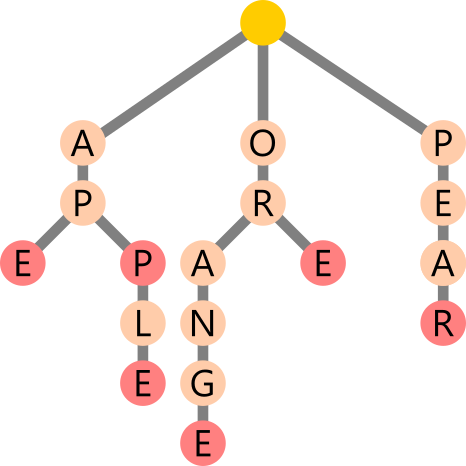
Each node represents a character which can have 26 children (or more depending on the character set). A node can be marked as an endpoint (in red) to signal the completion of a character string. Duplicate starting characters in similar words only use one node between them, as seen with A P for ape, apple and app, this has the wonderful side affect of compressing the sort data-structure. Our input data-set contained 24 characters, the tree only contains 17 characters.
To retrieve an alphabetically sorted list of words, you can traverse the tree taking the left most node, checking if its an endpoint (marked in red) if it is - return this, if not - explore the left most child, unless there is no more children, then travel up to the parent and explore the next adjacent child.
Some caveats,
1. It"s not going to be great for supporting the full unicode character set. A binary tree would probably work better.
2. There is a overhead traversing the structure to add and retrieve the items, but compared to other sorts this isn"t extreme.
3. In this implementation only one copy of each word is returned. This can easily be fixed by keeping a counter at each endpoint for duplicates.
4. Features like #3 eat ram in every node. This adds overhead to the tree and the compression is less efficient.